Approach
Natural language provides a simple way for humans to specify a goal for a robot, such as "go to the kitchen and bring the sugar to me." However, current state-of-the-art language-based embodied AI systems do not have such capability since they rely on a fixed-set vocabulary that cannot generalize to diverse instructions. In this demo, we propose a method that uses large language models (LLMs) to receive a free-form natural language instruction for object rearrangement.
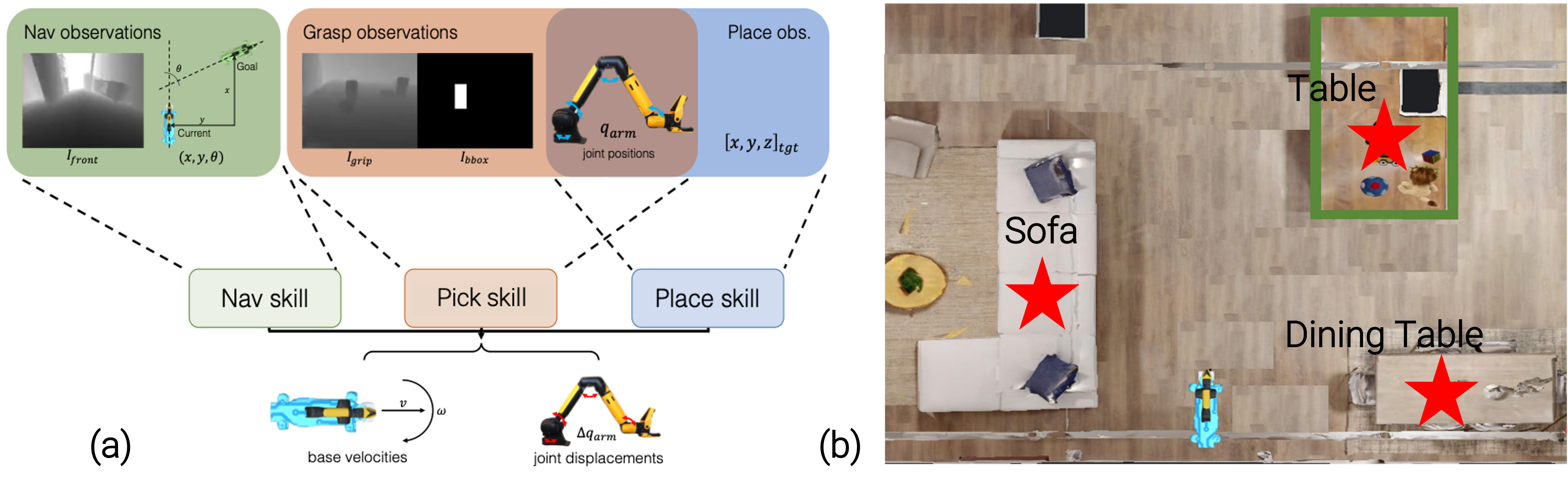
The proposed method "Language-guided Skill Coordination" (LSC) consists of three parts: (1) an LLM that takes natural language instruction as input and makes calls to a library of skills, along with their corresponding skills' input parameters such as the target object name, (2) a perception module that provides ground-truth locations of receptacles on that map and open-vocabulary object detection, and (3) a voice-to-text model that processes the audio into text.
For example, the top-most video shows a user saying "Bring me the chocolates box, cereal box, and pill bottle, and put them on the bedroom table". The LLM takes the text input and makes calls to low-level skills: Nav(counter), Pick(cereal), Nav(room table), and Place(). When executing Nav(counter), a perception module is queried to get the location of the counter. Then this location is fed into a reinforcement-learning-trained navigation policy to let Spot navigate to the target. After Spot finds the counter, Pick(cereal) is used to pick up the target object. The pick policy is trained to move the arm to the target grasping location of the object with the input of the object bounding box returned by the perception module. Finally, Spot uses Nav(room table) to find the room table and then calls Place() to place the object there. The entire process repeats for rearranging chocolates and pills.
In terms of robustness of LSC, the navigation policy is able to take an alternative route to avoid collision with humans. In addition, the pick policy is able to change the grasping location if the object moves or the base is not closed enough to the receptacle. These show that LSC is robust to disturbance.
This demo pieces many efforts together within the Embodied AI team at FAIR. For example, one critical component of this demo is the library of skills. They are from Adaptive Skill Coordination for Robotic Mobile Manipulation paper.